 ReasonerAgent
ReasonerAgent
A fully open source, ready-to-run agent that does research in a web browser and answers your queries
We present ReasonerAgent, a fully open source agent that answers user queries by doing research in a web browser interface. ReasonerAgent is built using pretrained large language models (LLMs) without additional training, but enjoys perhaps surprising empirical performance. With GPT-4o as the backend LLM, we conducted a preliminary evaluation of ReasonerAgent on a range of difficult web browsing tasks. Results show that ReasonerAgent increases the success rate from 0% to 32.2% in flight searching and improves by up to 124% over other agents and variants. Planning actions based on simulation with a world model instead of solely on autoregressive LLM reasoning, ReasonerAgent does not require expensive data collection, finetuning, nor RL exploration and runs using available APIs out of the box. The code and prompts are fully published, and a research preview is available online for the public to interact with the agent while understanding its limitations.
Example of ReasonerAgent performing the task “Plan a travel from Pittsburgh to ICML 2025”. Note that this task requires performing multiple subtasks over different websites, including some that are challenging to navigate. Specific websites and more detailed instructions were included in the prompt to help guide the agent's behavior.
What Can ReasonerAgent Do?
Operating a Chromium-based browser, ReasonerAgent can perform a broad range of realistic tasks that require complex, long-range, and goal-achieving behavior. The video above shows an example of ReasonerAgent performing the task of “Plan a trip from Pittsburgh to ICML 2025”. Other examples include searching for flights, compiling online shopping options, and researching news coverage. ReasonerAgent is still an early research preview and may make mistakes or have challenges navigating certain websites. Currently, we recommend including specific websites and detailed instructions in the prompt for more consistent agent behavior. Below is a comparison between OpenHands BrowsingAgent, a popular open-source web agent (left), and ReasonerAgent (right):
Searching for Flights
Compiling Online Shopping Options
Researching News Coverage
As realistic, rigorous, and reproducible evaluation of web agents is challenging, we adopt a mixture of evaluations based on LLM judgments, groundtruth answers, and simulated environments. Our preliminary results (summarized in Figure 1 below) show that ReasonerAgent clearly outperforms BrowsingAgent. In particular, ReasonerAgent increases the success rate on complex website navigation like flight searching from 0% to 32.2%, while planning based on world model simulation improves over autoregressive LLM reasoning by up to 124%. In a test on the flight search dataset, autoregressive planning with o3-mini has close-to-zero success rate, showing that even a strong textual-reasoning model can have limited success with web interactions. Despite the demonstrated potential, ReasonerAgent still falls short of human-level ingenuity and is limited in its capabilities, which we are excited to address going forward. More details are in the Architecture Design and Evaluation sections below.

Figure 1: Overview of performance comparison between ReasonerAgent and baselines. The full architecture shows clear advantage over the baseline BrowsingAgent, improving the performance on complex website navigation from 0% to 32.2%. Our proposed world model reasoning for planning also consistently improves over simple planning with autoregressive LLM by up to 124%. All the agents use GPT-4o unless noted otherwise. *We implement the autoregressive planner with o3-mini and test on the complex website navigation dataset, where the resulting agent has close-to-zero success rate.
Research Preview
Try our research preview available here online!
Overview
With continual advancements in large language models (LLM), the field of intelligent agent systems have witnessed impressive progress, with LLM-based agents capable of acting autonomously in environments such as browsers, computers, and the physical world. Agent models such as Operator, Deep Research, and UI-TARS make significant improvements through finetuning and reinforcement learning (RL), but their training and implementation details are not always clear, which hinders efforts in research and open-source innovation. Furthermore, these agents often require expensive specialized training and serving, which limits their applicability in practice. Inspired by OpenHands and Browser Use, we develop ReasonerAgent as a fully open source agent that works out of the box without needing additional training or serving. Planning actions with simulation-based reasoning using a world model instead of solely with LLM linear reasoning, ReasonerAgent shows clear advantages compared to existing agents and variants on a range of web browsing tasks, such as complex website navigation, multi-hop, multi-website QA, and general web automation. This blog post presents a preliminary evaluation of ReasonerAgent and a quick introduction to its architecture details. We also encourage the community to interact with our research preview to test out its capabilities.
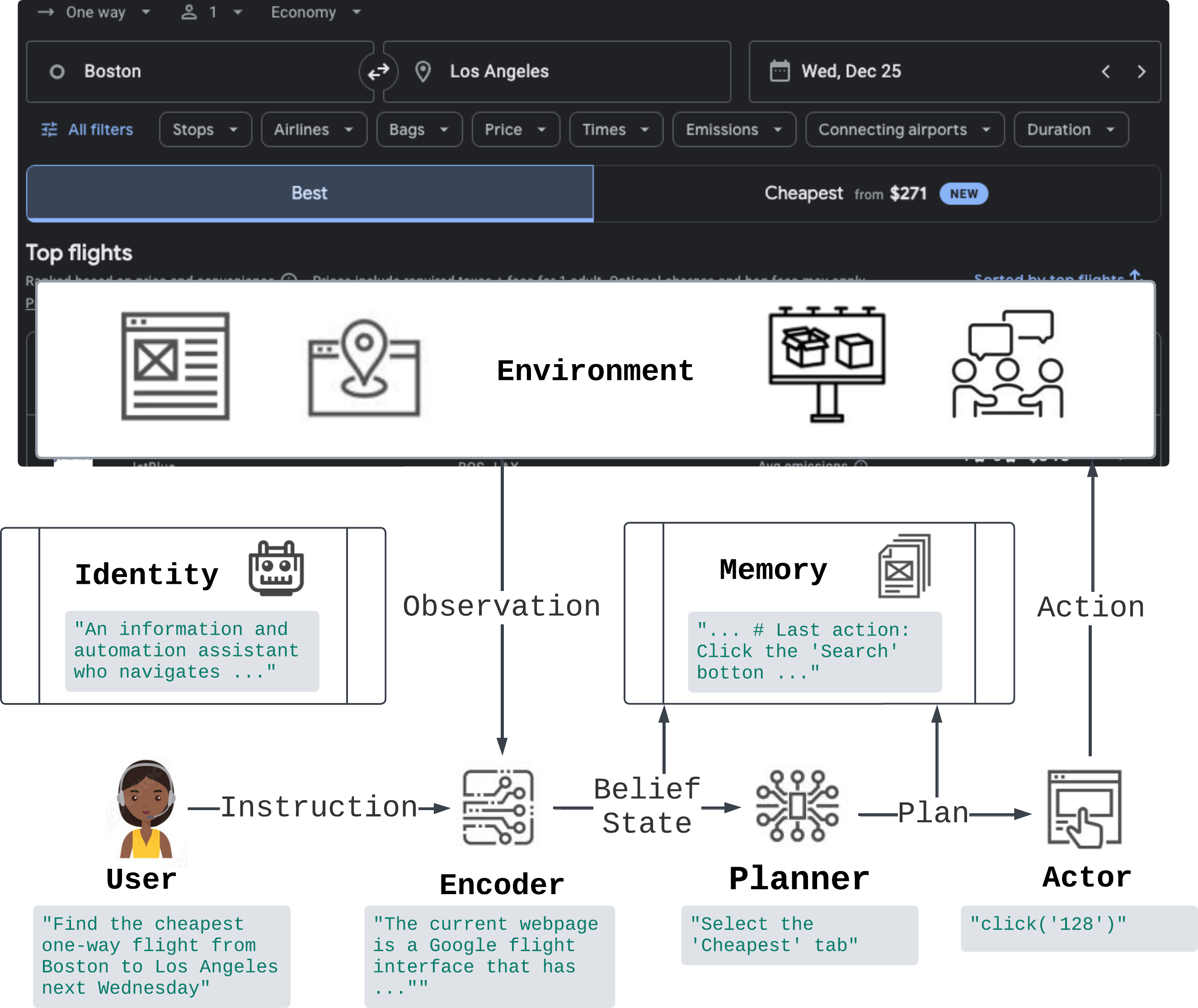
Figure 2: Architecture of ReasonerAgent and example of interaction with a web environment. Arrow annotates direction of information flow. Each module is implemented using pretrained LLMs through prompting. Our world-model-based planning is implemented in the Planner component, which we describe in more detail below.
Architecture Design
The architecture of ReasonerAgent consists of several modularized components, each implemented using pretrained LLMs with their own prompts, working together under pipelined collaboration. When a user provides an instruction to the system, the agent first takes the environment observation and translates it into a natural language description with the encoder, representing the agent’s belief state. The planner then determines the optimal plan to move from the current state toward the desired goal. Finally, the actor translates this plan into executable actions. This process repeats until the goal is achieved or some stopping condition is reached (e.g., maximum number of steps). There is also a memory component which maintains a record of the trajectory, including past states and plans, while providing contextual information for the above modules.
Key Features
ReasonerAgent builds on the OpenHands BrowsingAgent, with the following key improvements:
World Model Planning: We incorporate world model and critics modules into the planner to simulate the outcomes of proposed plans and optimize them. The world model enables the agent to predict future states and evaluate the feasibility of actions before execution, which helps overcome the inherent limitation of LLM autoregressive planning, which struggles to recover from mistakes in its previous outputs. Figure 3 shows the difference between world-model-based planning and typical autoregressive planning.
Belief State Modeling: We model the agent’s internal belief state about the environment by using LLM to summarize the observation into natural language descriptions. This step represents environment information in a format familiar to LLMs, which allows the LLM-based world model to better predict the next state, also represented in this latent space. In practice, we observe that this approach tends to lead to fewer hallucinations.

Figure 3: Detailed modular structure of planners. Autoregressive Planner (top) is a baseline that plans through linear thoughts from LLMs; World Model Planner (bottom) incorporates our proposed simulation-based reasoning which identifies and corrects mistakes from the autoregressive policy.
Implementation
We implement the simulation-based planning using LLM Reasoners, a library for advanced reasoning using LLMs. The prompts for world model and critic are partially adapted from Web Dreamer, a method for model-based planning in web browsing. For the web browser, we adopt BrowserGym, an open-source environment for web agents. The environment provides both text-based and screenshot-based representations of the webpage, of which we focus on the text-based part to avoid potential hallucinations from visual-based browsing.
Quantitative Evaluation
Note: Real-world websites are constantly evolving, and the underlying LLMs behind APIs may change without notice, leading to potential shifts in an agent’s performance over time. Our experiments were conducted between November 10, 2024 and December 9, 2024 unless otherwise specified.
Complex Website Navigation
As AI agents increasingly operate in dynamic environments like the open web, existing static benchmarks based on groundtruth answers often struggle with timeliness and reproducibility. For example, a question from WebVoyager asks to search for a flight that leaves on December 25, 2023, which was no longer available as of the date of our experiment. To overcome this challenge, we constructed a new evaluation set by using GPT-4o to generate 90 user queries with relative time requirements (e.g., next Monday) and to evaluate answer correctness based on its browsing history. Based on our observation so far, the LLM judgments are largely accurate and consistent in practice. For this preliminary evaluation, we focus on flight search as an example, and plan to extend to more use cases going forward. The dataset (named FlightQA) and code for question generation and evaluation are available online.
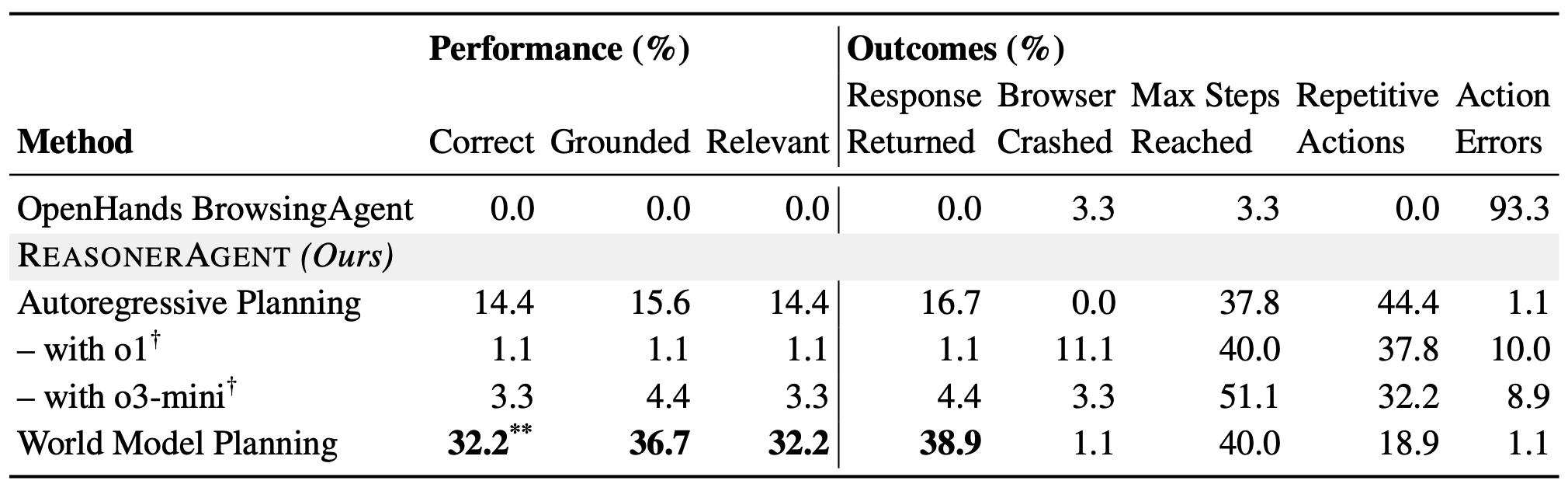
Table 1: Performance and outcome statistics for FlightQA dataset constructed by us. ** indicates being significantly higher than the second-best method at the statistical significance level of 0.01 (p < 0.01) based on pairwise t-test. †We implement the autoregressive planner with o1 and o3-mini, respectively.
Table 1 above compares the performance of ReasonerAgent and baselines using GPT-4o as the backend LLM. Compared to BrowsingAgent which fails completely in this task, the full ReasonerAgent improves the correct rate from 0% to 32.2%. Within our architecture, our proposed world-model-based planning shows superior performance over autoregressive reasoning with a 124% improvement (significant at the 0.01 level). Perhaps surprisingly, evaluation (performed February 3-5, 2025) shows o1 and o3-mini receive close to 0% success rates when serving as autoregressive planners. We do not include BrowsingAgent with o1 and o3-mini as the resulting agent frequently hallucinate answers without running the search at all, which precludes them as viable agents. These hallucinations, however, fool the LLM evaluator at significant rates, suggesting additional work is needed to secure its robustness. In Figure 4 below, we further compare the reasoning abilities of autoregressive and world-model-based planners by visualizing the correct % vs. number of constraints below. Results show world model planning enjoying consistent advantage over autoregressive planning, showing signs of improved reasoning ability.

Figure 4: % correct vs. number of constraints for FlightQA. Based on our data samples, world model planning consistently outperforms autoregressive planning as we increase the number of constraints, showing signs of improved reasoning ability.
Multi-Hop, Multi-Website QA
For multi-hop, multi-website QA, we evaluate on the FanOutQA dataset using its automatic metrics for fact-level accuracies. Table 2 shows results on the first 100 dev-set questions using GPT-4o-2024-05-13 (we find that the world-model-based agent tends to respond prematurely with newer versions, which can be mitigated with additional instructions) show our method again clearly improving the accuracy, with world model planning holding an edge of 47.5% over autoregressive planning (p-value = 0.011 < 0.05).
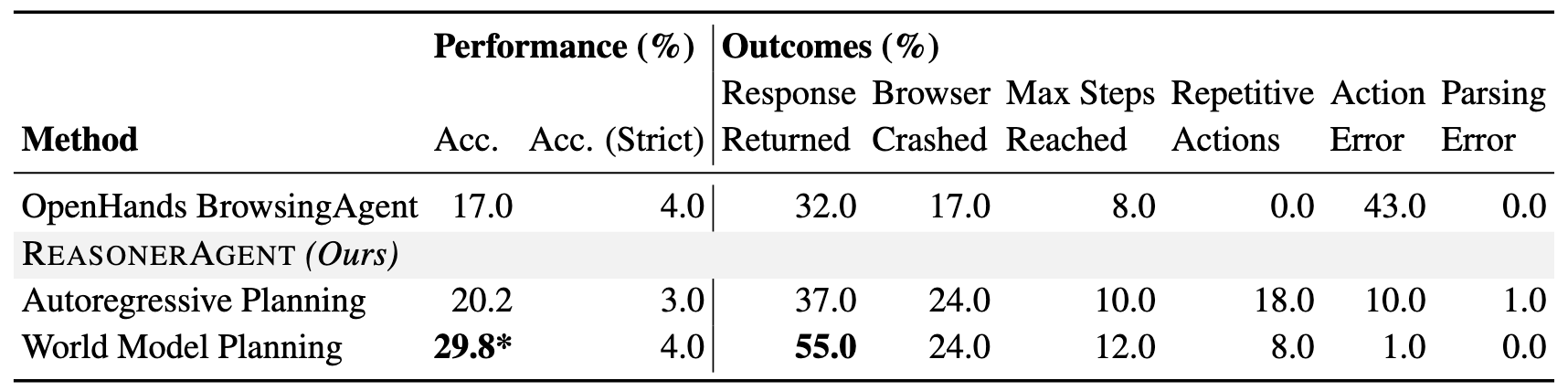
Table 2: Performance and outcome statistics for the FanOutQA dataset. Acc. (Strict) refers to the percentage of responses that exactly match the groundtruth. Our architecture clearly outperforms the baseline BrowsingAgent. Reasoning by world model increases the response rate and fact-level accuracy vs. autoregressive planning by 48.6% and 47.5%, respectively. * indicates being significantly higher than the second-best method at the 0.05 level based on pairwise t-test.
General Web Automation
For general web automation, we evaluate on the WebArena benchmark following the setting from OpenHands. Results on a random subset of 100 questions using GPT-4o (Table 3) again shows improvement of our architecture over the baselines. We aim to finish evaluating on the full set going forward.

Table 3: Results on a random 100-sample subset of WebArena. Our architecture improves over BrowsingAgent by up to 91.7%, while world model planning improves over autoregressive planning by 21.1%.
Serving
To serve web agents to the public for testing and comparison, we build a serving infrastructure based on OpenHands, but modified to support multiple concurrent users. The system employs a Load-Aware Round Robin strategy to efficiently load balance concurrent requests across dedicated backends, with each handling a single request. This is a lightweight implementation and we are actively working towards more scalable solutions that better adapt to fluctuating demands.
Limitations
As web agents are still in the early stage, we recognize that similar to existing agents, ReasonerAgent may face challenges navigating certain webpages or interacting with Captcha or anti-automation tools, and it has not been optimized to guarantee safety in the interactions. As agent-based automation become more integrated into daily workflows, we support discussions on fair use and safety guidelines for agent access. While the agent currently observes a text representation of the webpage, we plan to incorporate multimodal information like screenshots going forward.
Release
In our first release, we share the agent code as part of LLM Reasoners: https://github.com/maitrix-org/llm-reasoners, and the serving code at another GitHub repo: https://github.com/maitrix-org/easyweb. Join our Discord server and follow us on X to get the latest updates.
License
The online research preview intended for non-commercial use only, subject to Terms of Use of the API service provided by OpenAI. Please contact us if you find any potential violation. The agent code is released under the Apache License 2.0, and the serving code is released under the MIT License.
Acknowledgment
We would like to thank Zhoujun Cheng, Yi Gu, Shibo Hao, and Xinyu Pi from MixLab; Han Guo, Nicholas Ho and Bowen Tan from SAILING Lab; Zora Wang from NeuLab; Sarah Cheah and Hector Ren from MBZUAI for their insightful comments and feedback. Mingkai Deng is supported by Samsung GRO Project “Efficient Designs for Generative and Agent LLM Development”. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of Samsung.
The Team
This is a joint effort with collaborators from CMU, UC San Diego, MBZUAI, UCLA, Columbia, Samsung, AWS, and All Hands AI.
- Students (alphabetical order): Brandon Chiou, Mason Choey, Mingkai Deng (✉️), Jinyu Hou (✉️), Jackie Wang, Ariel Wu, Frank Xu
- Supervisors (alphabetical order): Zhiting Hu, Hongxia Jin, Li Erran Li, Graham Neubig, Yilin Shen, Eric P. Xing
✉️ Correspondence to: Mingkai Deng (mingkaid34@gmail.com), Jinyu Hou (hou.jinyu@outlook.com)
Citationå
1
2
3
4
5
6
7
@misc{reasoneragent2025,
title = {ReasonerAgent: A Fully Open Source, Ready-to-Run Agent That Does Research in a Web Browser and Answers Your Queries},
url = {https://reasoner-agent.maitrix.org/},
author = {Chiou, Brandon and Choey, Mason and Deng, Mingkai and Hou, Jinyu and Wang, Jackie and Wu, Ariel and Xu, Frank and Hu, Zhiting and Jin, Hongxia and Li, Li Erran and Neubig, Graham and Shen, Yilin and Xing, Eric P.},
month = {February},
year = {2025}
}